2 可計(jì)算醫(yī)學(xué)知識(shí)的基本概念
根據(jù)能否清晰表述和有效轉(zhuǎn)移,可以把知識(shí)分為顯性知識(shí)(explicit knowledge)和隱性知識(shí)(tacit knowledge)。醫(yī)學(xué)知識(shí),是經(jīng)過醫(yī)學(xué)實(shí)踐證實(shí)、科學(xué)分析或嚴(yán)謹(jǐn)研討過程后形成的結(jié)果或論斷,對(duì)特定的臨床專業(yè)或疾病人群具有重要指導(dǎo)意義,可界定為經(jīng)過科學(xué)實(shí)驗(yàn)/試驗(yàn)并經(jīng)同行評(píng)議后已發(fā)表或已被醫(yī)學(xué)界接受的結(jié)果、主張或認(rèn)知。由于醫(yī)學(xué)(特別是現(xiàn)代醫(yī)學(xué))有嚴(yán)格的培養(yǎng)標(biāo)準(zhǔn)和教育體系,醫(yī)學(xué)知識(shí)主要以顯性知識(shí)為主,即可以被記錄下來(lái),并被他人直接加以使用的知
識(shí)
[
9
]。醫(yī)學(xué)研究產(chǎn)出的醫(yī)學(xué)文獻(xiàn)和臨床指南成為醫(yī)學(xué)知識(shí)的主要載體。然而,大多數(shù)已發(fā)表的電子文獻(xiàn)停留于人類可理解的自然語(yǔ)言表示模式,即非結(jié)構(gòu)化的格式(一般以PDF文檔格式存儲(chǔ)),機(jī)器無(wú)法理解與計(jì)算,導(dǎo)致大量隱含在醫(yī)學(xué)文獻(xiàn)中的知識(shí)主張、可在實(shí)踐中應(yīng)用的模型或規(guī)則不能得到有效管理與利用。
以“‘computable knowledge’AND‘biomedical OR medical’”為核心關(guān)鍵詞,通過系統(tǒng)的文獻(xiàn)檢索與分析歸納,這一概念從字面上主要有兩種表述,“可計(jì)算的醫(yī)學(xué)知識(shí)”(computable medial knowledge)和“醫(yī)學(xué)知識(shí)的可計(jì)算化”(making medical knowledge computable)。前者側(cè)重實(shí)現(xiàn)的結(jié)果,后者側(cè)重實(shí)現(xiàn)的過程。從本質(zhì)上來(lái)看,兩者表達(dá)的意思是相同的。我們認(rèn)為,可計(jì)算醫(yī)學(xué)知識(shí)的基本概念包括兩個(gè)方面,一是知識(shí)的表示形式可計(jì)算化,二是知識(shí)在實(shí)踐中“可執(zhí)行”,兩者缺一不可。
表示形式主要有兩類:一是從非結(jié)構(gòu)化數(shù)據(jù)中生成知識(shí)單元(knowledge unit),表示為從自由文本中抽取的“主語(yǔ)-謂語(yǔ)-賓語(yǔ)”語(yǔ)義三元組(subject-predicate-object,SPO triple
)
[
10-11
];二是從結(jié)構(gòu)化數(shù)據(jù)中生成可計(jì)算的知識(shí)對(duì)象(computable knowledge objects),表示為從醫(yī)療大數(shù)據(jù)中生成的疾病預(yù)測(cè)模型,以及疾病診斷規(guī)則、計(jì)算機(jī)化的臨床指南
等[
7
,
12
]。
美國(guó)密歇根大學(xué)MCBK主要側(cè)重于后者,包括兩方面。一是構(gòu)建可計(jì)算的各類知識(shí)對(duì)象,通過計(jì)算機(jī)程序?qū)Ω黝愔R(shí)進(jìn)行編程封裝,形成計(jì)算機(jī)能處理的知識(shí)對(duì)象。一個(gè)知識(shí)對(duì)象包括知識(shí)載體、與用戶交互的界面,以及有關(guān)知識(shí)的詳細(xì)說(shuō)明3個(gè)部分。二是在一個(gè)大的知識(shí)管理平臺(tái)上實(shí)現(xiàn)對(duì)知識(shí)對(duì)象的共享和利用。例如,在統(tǒng)一的標(biāo)準(zhǔn)下類似Apple的APP Store提供各類APP應(yīng)用的下載和使用,醫(yī)生、患者、公眾等都能夠直接使用這些知識(shí)對(duì)象。
以“動(dòng)脈粥樣硬化性心血管疾病預(yù)測(cè)的中國(guó)模型”為例進(jìn)行說(shuō)明,作者不僅發(fā)表了學(xué)術(shù)論文(人讀的格式,如文字、圖片和公式
)
[
13
];在此基礎(chǔ)上還開發(fā)了可公開使用的網(wǎng)頁(yè)版計(jì)算器(web-based calculator
)
和手機(jī)APP程序,把疾病預(yù)測(cè)模型以機(jī)器可執(zhí)行的格式存儲(chǔ)并供用戶使用。
根據(jù)健康人或患者輸入的年齡、總膽固醇、高密度脂蛋白膽固醇、糖尿病等綜合指標(biāo)數(shù)據(jù),可計(jì)算出10年后個(gè)人ASCVD(arteriosclerotic cardiovascular disease,動(dòng)脈硬化性心血管疾病)的發(fā)病風(fēng)險(xiǎn)。基于網(wǎng)頁(yè)版計(jì)算器和手機(jī)APP程序這樣的機(jī)器可執(zhí)行的知識(shí)對(duì)象,用戶通過“填寫-計(jì)算-預(yù)測(cè)”產(chǎn)生了大量新的數(shù)據(jù),這些新的數(shù)據(jù)可進(jìn)一步幫助改進(jìn)預(yù)測(cè)模型的準(zhǔn)確性,進(jìn)而又形成了性能更佳的預(yù)測(cè)模型(即“新知識(shí)”)。最終,實(shí)現(xiàn)了“從數(shù)據(jù)到知識(shí)、從知識(shí)到實(shí)踐,從實(shí)踐再到數(shù)據(jù)”的循環(huán)。然而,目前,這樣的疾病預(yù)測(cè)模型散落于醫(yī)學(xué)科研機(jī)構(gòu)或醫(yī)療機(jī)構(gòu)中科研人員自建的網(wǎng)站,無(wú)法對(duì)于用戶實(shí)現(xiàn)“一站式獲取和大規(guī)模使用”。MCBK的目標(biāo)就是要建立規(guī)范統(tǒng)一的、標(biāo)準(zhǔn)化的知識(shí)對(duì)象存儲(chǔ)和共享平臺(tái)。
2.2 知識(shí)在實(shí)踐中“可執(zhí)行”
除了上述介紹的源自結(jié)構(gòu)化數(shù)據(jù)的疾病預(yù)測(cè)模型作為可直接調(diào)用和運(yùn)行(即“可執(zhí)行”)的知識(shí)對(duì)象外,來(lái)源于非結(jié)構(gòu)化文本的知識(shí)圖譜通常也作為計(jì)算機(jī)系統(tǒng)中用來(lái)形式化表示知識(shí)的一種工
具
[
14
]。知識(shí)圖譜在臨床實(shí)踐中的價(jià)值主要體現(xiàn)為在將知識(shí)圖譜和基于真實(shí)世界數(shù)據(jù)的電子病歷的結(jié)合應(yīng)用上。目前,將醫(yī)學(xué)知識(shí)圖譜與電子病歷相結(jié)合(即促使醫(yī)學(xué)知識(shí)“可執(zhí)行”)是醫(yī)學(xué)知識(shí)圖譜應(yīng)用的前沿研究課題。這樣的結(jié)合為臨床醫(yī)護(hù)人員帶來(lái)的益處主要包含3個(gè)方面:一是方便查詢醫(yī)學(xué)領(lǐng)域知識(shí);二是邏輯化呈現(xiàn)患者數(shù)據(jù)和信息;三是輔助臨床決策,從而幫助提高診斷效率和準(zhǔn)確率。
使用知識(shí)圖譜可以提升從文獻(xiàn)或大量臨床數(shù)據(jù)中檢索信息、查詢知識(shí)的能力。例如,利用大型開放式知識(shí)庫(kù)(如Wikipedia和SemMedDB)提供的有關(guān)每種疾病及其相關(guān)癥狀、檢查和治療的知識(shí)圖譜,將電子病歷中提取的與診斷相關(guān)的信息與之進(jìn)行比對(duì),可提高臨床診斷的效
率
[
15
]。采用結(jié)構(gòu)化圖譜方式取代傳統(tǒng)的敘述性文本對(duì)患者病情進(jìn)行描述,可改進(jìn)復(fù)雜患者數(shù)據(jù)或個(gè)人健康信息的表示和呈現(xiàn),減輕醫(yī)生的信息負(fù)擔(dān)和認(rèn)知負(fù)擔(dān)。在臨床診療過程中,可通過將人讀的、自然語(yǔ)言描述的醫(yī)學(xué)證據(jù)和臨床指南轉(zhuǎn)化為機(jī)器可讀、可理解的知識(shí)圖譜,把已有的知識(shí)通過知識(shí)圖譜工具提供給臨床以作為診療決策的重要參
考[
16
]。醫(yī)學(xué)知識(shí)圖譜與先進(jìn)的知識(shí)圖譜推理方法的結(jié)合可以極大地減輕臨床醫(yī)生的診斷壓力,減少誤診率并提高診斷效率。由于醫(yī)學(xué)的系統(tǒng)性,目前的醫(yī)學(xué)知識(shí)圖譜主要面向?qū)2。磥?lái)需要更為完整和準(zhǔn)確的全科醫(yī)學(xué)知識(shí)圖譜,并需要不斷改進(jìn)知識(shí)圖譜推理算法,以期更好地與臨床決策支持相結(jié)
合[
17
]。
此外,與MCBK側(cè)重“醫(yī)學(xué)知識(shí)的表示形式可計(jì)算化,即從人讀的論文轉(zhuǎn)化為機(jī)器可執(zhí)行的程序”不同,有學(xué)者提出醫(yī)學(xué)證據(jù)合成(evidence synthesis)也需要引入可計(jì)算化的思路,以減輕人工負(fù)荷。根據(jù)統(tǒng)計(jì),目前全球每天要進(jìn)行75項(xiàng)臨床試驗(yàn)和11項(xiàng)系統(tǒng)綜述,如何跟上海量醫(yī)學(xué)證據(jù)的發(fā)展,并將其轉(zhuǎn)化為臨床實(shí)踐是一個(gè)迫切需要解決的科學(xué)問
題
[
18
]。系統(tǒng)綜述和meta分析已被公認(rèn)為是客觀評(píng)價(jià)和合成針對(duì)某一特定問題的研究證據(jù)的最佳手段,通常被視作最高級(jí)別的證據(jù)。2020年,醫(yī)學(xué)信息學(xué)領(lǐng)域的學(xué)者發(fā)表了“可計(jì)算的證據(jù)合成”(computable evidence synthesis)的概念,提出了直接利用結(jié)構(gòu)化數(shù)據(jù)促進(jìn)醫(yī)學(xué)證據(jù)合成的觀
點(diǎn)[
19
]。
在臨床試驗(yàn)過程中,有關(guān)試驗(yàn)設(shè)計(jì)和實(shí)施的信息通常與試驗(yàn)結(jié)果一起以期刊文章的形式發(fā)布。因此,當(dāng)前的醫(yī)學(xué)證據(jù)合成主要依賴于人工檢索書目數(shù)據(jù)庫(kù)并閱讀、篩選證據(jù),導(dǎo)致數(shù)據(jù)不夠完整,且?guī)в幸欢ǔ潭鹊钠校缫寻l(fā)表文章多為陽(yáng)性結(jié)果。關(guān)于試驗(yàn)涉及的臨床問題和干預(yù)措施的詳細(xì)信息,可通過在試驗(yàn)注冊(cè)時(shí)預(yù)先指定的數(shù)據(jù)元素獲取,使得數(shù)據(jù)結(jié)果能夠以標(biāo)準(zhǔn)化、結(jié)構(gòu)化的格式呈現(xiàn)。臨床試驗(yàn)注冊(cè)平臺(tái)所提供的結(jié)構(gòu)化結(jié)果數(shù)據(jù)更具有及時(shí)性、完整性和易獲取的特點(diǎn),且可以實(shí)現(xiàn)數(shù)據(jù)的自動(dòng)更新和計(jì)算機(jī)可解釋。
因此,現(xiàn)在應(yīng)該重新反思證據(jù)合成的基本原理。隨著獲取不同形式的可計(jì)算試驗(yàn)數(shù)據(jù)成為可能,將有助于系統(tǒng)綜述從耗時(shí)的試驗(yàn)結(jié)果出版物篩選模式轉(zhuǎn)為主動(dòng)積極的臨床試驗(yàn)監(jiān)測(cè)模式,從證據(jù)積累模式轉(zhuǎn)變?yōu)樽C據(jù)優(yōu)先級(jí)排序的模式。與此概念相對(duì)應(yīng),2020年8月,可計(jì)算化出版(computable publishing)組織成立,通過開發(fā)臨床試驗(yàn)結(jié)果報(bào)告器(clinical trials reporter)等工具,支持基于標(biāo)準(zhǔn)的、機(jī)器可解釋的公共知識(shí)表達(dá),尤其是與健康醫(yī)療和科學(xué)證據(jù)有關(guān)的公共知
識(shí)
[
20
]。
3 可計(jì)算醫(yī)學(xué)知識(shí)的前端表示模型
基于美國(guó)密歇根大學(xué)對(duì)可計(jì)算醫(yī)學(xué)知識(shí)的定義,只有通過計(jì)算機(jī)編程封裝知識(shí)對(duì)象之后,才能實(shí)現(xiàn)可計(jì)算,從這個(gè)角度來(lái)看,可計(jì)算醫(yī)學(xué)知識(shí)的最終表示方式都是程序代碼。然而,本節(jié)重點(diǎn)闡述如何表示封裝之前的可計(jì)算醫(yī)學(xué)知識(shí),即可計(jì)算醫(yī)學(xué)知識(shí)的前端表示模型。
3.1 醫(yī)學(xué)規(guī)則與診療知識(shí)庫(kù)
在醫(yī)學(xué)教科書、醫(yī)學(xué)文獻(xiàn)中出現(xiàn)的大多醫(yī)學(xué)知識(shí),均是以傳統(tǒng)IF(前件)-THEN(后果)規(guī)則的格式進(jìn)行表示。以發(fā)燒為例,醫(yī)學(xué)知識(shí)中的診斷規(guī)則通常表示如下:如果患者體溫超過38℃,那么該患者處于發(fā)燒狀態(tài)。傳統(tǒng)的醫(yī)學(xué)規(guī)則包含前件和后果,前件為臨床的某種病癥,后果為某種特定的疾病、治療方案、或者結(jié)局等。在臨床實(shí)踐中,大多數(shù)醫(yī)護(hù)人員的疾病診斷及治療均是依賴現(xiàn)有醫(yī)學(xué)知識(shí)中累積的各種規(guī)則。把針對(duì)特定疾病的診療規(guī)則進(jìn)行歸納、整理,最終形成該種疾病的診療知識(shí)庫(kù)。
隨著計(jì)算機(jī)技術(shù)的發(fā)展,計(jì)算機(jī)存儲(chǔ)和計(jì)算能力已經(jīng)遠(yuǎn)超人腦的記憶思維能力,把傳統(tǒng)IF-THEN診療規(guī)則或者診療知識(shí)庫(kù)電子化、結(jié)構(gòu)化,就形成了計(jì)算機(jī)能夠存儲(chǔ)并理解的計(jì)算機(jī)化醫(yī)學(xué)規(guī)則或者知識(shí)庫(kù)。在文獻(xiàn)和醫(yī)學(xué)實(shí)踐中,基于專家系統(tǒng)方式實(shí)現(xiàn)的臨床決策支持系統(tǒng),就是依賴于這樣的醫(yī)學(xué)規(guī)則和知識(shí)庫(kù)。
3.2 數(shù)據(jù)驅(qū)動(dòng)的疾病預(yù)測(cè)模型
傳統(tǒng)醫(yī)學(xué)實(shí)踐中,醫(yī)護(hù)人員是依據(jù)權(quán)威的醫(yī)學(xué)知識(shí)或者自身經(jīng)驗(yàn)進(jìn)行臨床疾病診斷、治療以及疾病管理決策,因此,不同醫(yī)療機(jī)構(gòu)以及醫(yī)護(hù)人員的醫(yī)療服務(wù)水平和患者的預(yù)后與醫(yī)護(hù)人員自身的醫(yī)療背景以及經(jīng)驗(yàn)具有很大關(guān)聯(lián),差異性非常大。在計(jì)算機(jī)與信息技術(shù)高度發(fā)達(dá)、大數(shù)據(jù)與人工智能已經(jīng)深度融入醫(yī)學(xué)領(lǐng)域的當(dāng)今時(shí)代,臨床的診療及疾病管理決策已經(jīng)不單單是依靠現(xiàn)有領(lǐng)域知識(shí)和專家自身經(jīng)驗(yàn),基于傳統(tǒng)醫(yī)學(xué)研究臨床試驗(yàn)中所收集的數(shù)據(jù)以及真實(shí)醫(yī)療實(shí)踐中累積的醫(yī)療大數(shù)據(jù)進(jìn)行分析、挖掘,找出疾病的規(guī)律和特征,構(gòu)建疾病發(fā)生、發(fā)展以及患者預(yù)后的預(yù)測(cè)模型,將輔助醫(yī)護(hù)人員進(jìn)行有效的、優(yōu)化的臨床決策。
數(shù)據(jù)驅(qū)動(dòng)的疾病發(fā)生、發(fā)展及患者預(yù)后的預(yù)測(cè)模型,其輸入變量一般是患者的人口學(xué)信息、臨床病癥以及實(shí)驗(yàn)室檢查檢驗(yàn)的結(jié)果,其輸出變量一般是某種疾病或并發(fā)癥發(fā)生、某種預(yù)后發(fā)生的概率。將數(shù)據(jù)驅(qū)動(dòng)的疾病預(yù)測(cè)模型進(jìn)行系統(tǒng)實(shí)現(xiàn),并有效嵌入或者集成到日常的醫(yī)療服務(wù)工作流程中,就形成了一個(gè)自動(dòng)化、智能的臨床決策支持工具,以輔助臨床醫(yī)護(hù)人員進(jìn)行各種診療決策。一般來(lái)講,數(shù)據(jù)驅(qū)動(dòng)的疾病預(yù)測(cè)工具應(yīng)與基于知識(shí)的決策支持工具融合使用,一是拓展了現(xiàn)有領(lǐng)域知識(shí)和專家經(jīng)驗(yàn),二是彌補(bǔ)了基于局部真實(shí)世界醫(yī)療大數(shù)據(jù)或者臨床試驗(yàn)數(shù)據(jù)進(jìn)行疾病建模帶來(lái)的局限性。
3.3 語(yǔ)義三元組:細(xì)粒度表示醫(yī)學(xué)知識(shí)主張
大量的生物醫(yī)學(xué)知識(shí)隱藏在自由文本中,自然語(yǔ)言處理技術(shù)對(duì)實(shí)體(如疾病、藥物、基因、蛋白質(zhì)等)和關(guān)系(如疾病治療、蛋白質(zhì)/藥物相互作用和藥物不良反應(yīng)事件)的抽取,有助于支撐生物醫(yī)學(xué)知識(shí)管理和發(fā)現(xiàn)等應(yīng)用,促進(jìn)臨床醫(yī)生和實(shí)驗(yàn)室科研人員更有效地獲取信息和生成新知識(shí)。可計(jì)算知識(shí)應(yīng)是結(jié)構(gòu)化的知識(shí),從格式上可由計(jì)算機(jī)程序讀取。一種簡(jiǎn)單的、可計(jì)算的知識(shí)表示是語(yǔ)義三元組。語(yǔ)義三元組由兩個(gè)概念組成,這兩個(gè)概念通過某些謂語(yǔ)(即動(dòng)詞)相互關(guān)聯(lián),如“導(dǎo)致(causes)”和“治療(treats)”。如“布洛芬-引起-胃腸道出血”就是這樣一種語(yǔ)義三元組。語(yǔ)義三元組被稱為“思想的原子”,既可以具象地表示某一命題或主張,又具有不可再分性。例如,可以將藥物知識(shí)表示為三元
組
[
21
],以從PubMed文獻(xiàn)中抽取的三元組作為基準(zhǔn),將從FDA(Food and Drug Administration,美國(guó)食品藥品監(jiān)督管理局)藥物說(shuō)明書中抽取的三元組與之對(duì)比,可識(shí)別新的且文獻(xiàn)中未報(bào)道過的醫(yī)學(xué)知
識(shí)[
22
];將電子病歷文本中的知識(shí)元表示為語(yǔ)義三元組,開展電子病歷潛在知識(shí)發(fā)現(xiàn)研
究[
23
]。基于“以三元組為知識(shí)單元,以不確定性為知識(shí)語(yǔ)境”的知識(shí)計(jì)算模型,開展矛盾性、沖突性知識(shí)發(fā)
現(xiàn)[
24
]。
在醫(yī)學(xué)領(lǐng)域,語(yǔ)義三元組抽取已具有較為成熟的技術(shù),其中,以美國(guó)國(guó)立醫(yī)學(xué)圖書館的“科學(xué)知識(shí)語(yǔ)義表示”項(xiàng)目開發(fā)的SemRep工具和SemMedDB知識(shí)庫(kù)為典型代表。SemRep是Semantic Representation的簡(jiǎn)稱,是一個(gè)基于規(guī)則的自然語(yǔ)言處理工具。以一體化醫(yī)學(xué)語(yǔ)言系統(tǒng)(unified medical language system,UMLS)中標(biāo)準(zhǔn)化的醫(yī)學(xué)概念、概念類型(如藥物、疾病)和概念之間的語(yǔ)義關(guān)系(如治療)為基礎(chǔ),從自然語(yǔ)言文本中抽取“主語(yǔ)-謂語(yǔ)-賓語(yǔ)”三元組。最新版UMLS收錄約380萬(wàn)個(gè)概念、127種概念類型和54種語(yǔ)義關(guān)系。SemMedDB知識(shí)庫(kù)存儲(chǔ)基于SemRep工具,抽取PubMed文獻(xiàn)標(biāo)題和摘要形成的三元組以及其來(lái)源語(yǔ)
句
[
25
]。該庫(kù)每年發(fā)布一次,且不斷改進(jìn),包括對(duì)SemRep工具提取的錯(cuò)誤概念和關(guān)系進(jìn)行糾正。SemRep和SemMedDB支持了多種臨床決策和轉(zhuǎn)化應(yīng)用,包括醫(yī)療診斷、藥物再利用、基于文獻(xiàn)的發(fā)現(xiàn)和假設(shè)生成,有助于改善健康結(jié)局。目前,SemRep工具正在被重新設(shè)計(jì),以提高其整體性能。SemRep和SemMedDB實(shí)現(xiàn)了大規(guī)模知識(shí)單元的抽取和存儲(chǔ),是一個(gè)基礎(chǔ)庫(kù),并且可進(jìn)行二次開發(fā)。例如,英國(guó)學(xué)者最近開發(fā)了MELODI Presto系
統(tǒng)
,該系統(tǒng)提供基于Web網(wǎng)頁(yè)查詢SemMedDB中的三元組及其背后的支持語(yǔ)
句[
26
]。
3.4 納米出版模型(nanopublication)
近年來(lái),生物語(yǔ)義學(xué)(biosemantics)領(lǐng)域的進(jìn)展為細(xì)粒度表示醫(yī)學(xué)知識(shí)對(duì)象提供了啟示和借鑒,以荷蘭萊頓大學(xué)生物語(yǔ)義學(xué)專家Barend Mons教授及其團(tuán)隊(duì)提出的納米出版模型為典型代
表
[
27-28
]。該模型并非專指納米領(lǐng)域,而是指借鑒納米之義,具有科學(xué)意義的、機(jī)器可讀的、最小的知識(shí)單元。納米出版物模型解決了由于科學(xué)論文和數(shù)據(jù)集的不斷增長(zhǎng)而導(dǎo)致檢索、分析知識(shí)單元以及將科學(xué)結(jié)果與基礎(chǔ)數(shù)據(jù)聯(lián)系起來(lái)日益困難的問題,實(shí)現(xiàn)了將人讀的知識(shí)轉(zhuǎn)化為機(jī)器可讀的知識(shí)。
基本結(jié)構(gòu)包括三部分:①主張(assertion),即主-謂-賓三元組表示的科學(xué)論斷;②出處信息(provenance),表示提出主張或創(chuàng)建了事實(shí)性素材(如數(shù)據(jù)、圖表等)的作者、機(jī)構(gòu)、時(shí)間和地點(diǎn)等;③出版信息(publication Information),關(guān)于一個(gè)納米出版物本身的元數(shù)據(jù),包括納米出版物的創(chuàng)建者、創(chuàng)建日期和版本等。這三個(gè)組件缺一不可,保證了信息完整性,并能有效提升科研信息的復(fù)用可能。這三個(gè)部分的內(nèi)容均使用RDF格式進(jìn)行描述,保證了機(jī)器可理解和可操作。
目前主要有三種進(jìn)行中的應(yīng)用。一是科研工作者自行將個(gè)人研究成果發(fā)布為納米出版物(存儲(chǔ)于平臺(tái)http://nanopub.org/wordpress/);二是將已有關(guān)系型數(shù)據(jù)庫(kù)(如基因-疾病關(guān)聯(lián)知識(shí)庫(kù)DisGeNet)以納米出版物形式發(fā)
布
[
29
];三是支持目標(biāo)導(dǎo)向的大型項(xiàng)目,如藥物發(fā)現(xiàn)語(yǔ)義平臺(tái)Open PHACTS(Open Pharmaceutical Triple Store)項(xiàng)
目[
30
],是一個(gè)存儲(chǔ)和計(jì)算藥學(xué)概念三元組的倉(cāng)儲(chǔ)。基于納米出版模型,建立試驗(yàn)數(shù)據(jù)和科學(xué)結(jié)論的規(guī)范語(yǔ)義描述本體,并在大規(guī)模生物醫(yī)藥文獻(xiàn)集上構(gòu)建了藥學(xué)知識(shí)單元形成的網(wǎng)絡(luò),即知識(shí)圖譜。納米出版模型尚未在臨床醫(yī)學(xué)領(lǐng)域廣泛應(yīng)用,這也是我們計(jì)劃研究的主要內(nèi)容。
如果以納米出版模型作為知識(shí)單元,構(gòu)建知識(shí)單元的引用關(guān)系反映的知識(shí)演化,那么需要解決的問題是如何像科學(xué)論文那樣,構(gòu)建納米出版物的引用格式。2019年,有學(xué)者提出了可對(duì)單個(gè)納米出版物進(jìn)行引用的納米引用格式(nanocitation),并設(shè)計(jì)了一個(gè)系統(tǒng)自動(dòng)生成納米出版物的引文,解決了這一模型缺乏引文標(biāo)準(zhǔn)的問題,在此基礎(chǔ)上可以設(shè)計(jì)文獻(xiàn)計(jì)量學(xué)指標(biāo),開展知識(shí)單元這一細(xì)粒度層面的分
析
[
31
]。為了充分發(fā)揮并利用可計(jì)算醫(yī)學(xué)知識(shí)的優(yōu)勢(shì),最終需要一種全新的方法讓所有知識(shí)在開始生成時(shí)便適合于計(jì)
算[
32
]。例如,將傳統(tǒng)的人讀的科學(xué)出版物轉(zhuǎn)化為機(jī)器可讀的納米出版物,研究產(chǎn)出將不再僅僅是科學(xué)論文及相關(guān)的數(shù)據(jù)集,而是一組可計(jì)算格式的結(jié)果或主張,描述實(shí)驗(yàn)過程和結(jié)果的自然語(yǔ)言文本(即學(xué)術(shù)論文)僅作為供人類可讀并參考的一種形式,對(duì)其進(jìn)行處理后可產(chǎn)生更高階的信息,如系統(tǒng)綜述和臨床實(shí)踐指南。
3.5 knowlet模型:以知識(shí)子圖作為可編碼知識(shí)單元
提出納米出版模型的Barend Mons教授及其團(tuán)隊(duì)同時(shí)提出,把所有持相同論斷的納米出版物中共同出現(xiàn)的論斷聚合為一個(gè)“基本論斷”,以減少冗
余
[
33
]。將圍繞一個(gè)中心概念(central concept)、路徑長(zhǎng)度為1的三元組之組合作為一個(gè)knowlet。我們認(rèn)為,knowlet是指知識(shí)圖譜中可以表示一個(gè)獨(dú)立知識(shí)單元的子圖,可將其譯為“知識(shí)子圖”。例如,圍繞“新冠”這一概念,作為起點(diǎn)或終點(diǎn)的所有關(guān)系,如癥狀、診斷、治療形成的三元組。隨著圍繞某一概念的論斷越來(lái)越多,與文本空間快速增長(zhǎng)相比,知識(shí)子圖空間增長(zhǎng)較小,例如,有大量的文本涉及的知識(shí)單元只有一個(gè)。知識(shí)子圖是一個(gè)獨(dú)立的數(shù)字對(duì)象和最小的知識(shí)單元,其本身可被發(fā)現(xiàn)、可訪問、可互操作以及可重用。
在上述5種醫(yī)學(xué)知識(shí)表示模型中,醫(yī)學(xué)診斷規(guī)則和數(shù)據(jù)驅(qū)動(dòng)的疾病預(yù)測(cè)模型主要涉及結(jié)構(gòu)化數(shù)據(jù),以三元組為基礎(chǔ)的表示模型主要適用于非結(jié)構(gòu)化文本。實(shí)際上,規(guī)則也可以表示為三元組,例如,“心率”-“正常值”-“60~100次/分”就是“實(shí)體-屬性-值”表示的三元組;基于醫(yī)學(xué)數(shù)據(jù)、通過機(jī)器學(xué)習(xí)產(chǎn)生的決策樹,可以轉(zhuǎn)化為一系列的醫(yī)學(xué)規(guī)則,亦可理解為三元組的邏輯組合。知識(shí)圖譜的本質(zhì)是三元組因果關(guān)系圖譜,由“實(shí)體-屬性-值”或“實(shí)體-關(guān)系-實(shí)體”構(gòu)成。每個(gè)屬性-值對(duì)應(yīng)刻畫了實(shí)體的內(nèi)在特性;關(guān)系則連接兩個(gè)實(shí)體,刻畫了實(shí)體之間的外部關(guān)聯(lián)。
4 醫(yī)學(xué)知識(shí)“可執(zhí)行”的實(shí)現(xiàn)路徑
本文第2節(jié)提出了可計(jì)算醫(yī)學(xué)知識(shí)的兩個(gè)要素:一是可計(jì)算化的表示形式,二是機(jī)器可執(zhí)行。第3節(jié)和第4節(jié)分就分為圍繞上述兩個(gè)要素展開,其中,第3節(jié)是側(cè)重于知識(shí)對(duì)象封裝成軟件代碼之前如何表示的問題;而第4節(jié)側(cè)重于知識(shí)對(duì)象封裝成軟件代碼之后,如何提供服務(wù)的整個(gè)流程以及尚需要解決的問題。
北京大學(xué)健康醫(yī)療大數(shù)據(jù)國(guó)家研究院正在牽頭積極推動(dòng)可計(jì)算醫(yī)學(xué)知識(shí)在中國(guó)的研究和實(shí)踐,并與該概念的提出者——密歇根大學(xué)學(xué)習(xí)型健康醫(yī)療體系研究中心Charles Friedman教授的團(tuán)隊(duì)保持著密切合作。Charles Friedman教授團(tuán)隊(duì)開發(fā)了一個(gè)用于可計(jì)算知識(shí)對(duì)象封裝、存儲(chǔ)、管理和調(diào)用的知識(shí)網(wǎng)格(knowledge grid,K-Grid)平
臺(tái)
。目前已經(jīng)實(shí)現(xiàn)原型系統(tǒng),并在持續(xù)研發(fā)中。北京大學(xué)健康醫(yī)療大數(shù)據(jù)國(guó)家研究院、浙江省北大信息技術(shù)高等研究院智慧醫(yī)療研究中心正在中國(guó)進(jìn)行本地化開發(fā)與推廣。目前,該平臺(tái)中的知識(shí)對(duì)象主要來(lái)源于結(jié)構(gòu)化數(shù)據(jù),且以疾病預(yù)測(cè)模型為主。
上文介紹了荷蘭萊頓大學(xué)Barend Mons教授團(tuán)隊(duì)提出的納米出版模型與知識(shí)子圖模型,主要來(lái)源于非結(jié)構(gòu)化文本。我們嘗試將這類知識(shí)對(duì)象也能編程封裝之后,在K-Grid平臺(tái)上實(shí)現(xiàn)調(diào)用和執(zhí)行。因此,為了更充分和全面地在我國(guó)設(shè)計(jì)和發(fā)起可計(jì)算醫(yī)學(xué)知識(shí)的研發(fā)和實(shí)踐,我們整合了上述兩條路徑(
圖1
)。

圖1 可計(jì)算醫(yī)學(xué)知識(shí)的兩條實(shí)現(xiàn)路徑(分別針對(duì)結(jié)構(gòu)化數(shù)據(jù)和非結(jié)構(gòu)化文本)
知識(shí)生成與知識(shí)的可計(jì)算化處理是分開的、在不同階段進(jìn)行的。本文重點(diǎn)討論將生成后的知識(shí)(臨床指南、醫(yī)學(xué)文獻(xiàn)、本地實(shí)驗(yàn)/試驗(yàn)后的分析結(jié)果等)實(shí)現(xiàn)可計(jì)算化這階段。
一是數(shù)據(jù)挖掘,形成計(jì)算機(jī)可直接調(diào)用和執(zhí)行(如直接計(jì)算出疾病風(fēng)險(xiǎn)分值)的知識(shí)對(duì)象,用知識(shí)網(wǎng)格(K-Grid)管理,提供輔助診斷。例如,根據(jù)生化指標(biāo)判斷患者是否可診斷為慢性腎病合并貧血,根據(jù)若干指標(biāo)計(jì)算個(gè)人罹患肺癌風(fēng)險(xiǎn)分值等。數(shù)據(jù)挖掘產(chǎn)生的規(guī)則或者模型屬于知識(shí)表示模型(如人工神經(jīng)網(wǎng)絡(luò)、決策樹等),還沒有形成可計(jì)算知識(shí)對(duì)象,需要K-Grid平臺(tái)上的工具對(duì)規(guī)則或者模型進(jìn)行編程封裝之后,才能形成可計(jì)算知識(shí)對(duì)象;多種計(jì)算機(jī)語(yǔ)言(R或者Python)可供選擇進(jìn)行預(yù)測(cè)模型的封裝。雖然R開發(fā)環(huán)境挖掘出來(lái)的模型本身就是可執(zhí)行的,但是如果想通過K-Grid平臺(tái)進(jìn)行管理的話,還需要進(jìn)一步編程封裝。這與文本挖掘產(chǎn)生知識(shí)三元組是一個(gè)平行的過程。
二是文本挖掘,形成結(jié)構(gòu)化的三元組,并納入三元組背后的證據(jù)和數(shù)據(jù),計(jì)算出置信度,采用類似Neo4j圖數(shù)據(jù)庫(kù)來(lái)管理,實(shí)現(xiàn)知識(shí)單元的查詢和輸出。例如,根據(jù)目前最佳證據(jù),治療某種疾病的藥物清單,該藥物清單可按照置信度排序,提供治療方式的自動(dòng)推薦。
總之,無(wú)論是路徑一提供的輔助診斷,還是路徑二提供的輔助治療,均為臨床決策支持的范疇。下文分別介紹了在兩條實(shí)施路徑中,我們已完成的內(nèi)容以及需要繼續(xù)研發(fā)的內(nèi)容。
4.1 路徑一:從結(jié)構(gòu)化數(shù)據(jù)中生成的可計(jì)算醫(yī)學(xué)知識(shí)
當(dāng)前,作為中國(guó)首個(gè)“推動(dòng)醫(yī)學(xué)知識(shí)可計(jì)算行動(dòng)”的網(wǎng)
站
,已完成平臺(tái)的設(shè)計(jì)與研發(fā)(
圖2
)。選擇慢性疾病作為切入點(diǎn),構(gòu)建了醫(yī)學(xué)知識(shí)模型與可計(jì)算編程規(guī)范。已建設(shè)醫(yī)學(xué)知識(shí)對(duì)象29個(gè),多場(chǎng)景兼容應(yīng)用14個(gè),全流程慢性腎臟疾病(chronic kidney disease,CKD)解決方案專題2個(gè)。為醫(yī)療機(jī)構(gòu)和醫(yī)學(xué)專家團(tuán)隊(duì)提供創(chuàng)建并管理醫(yī)學(xué)知識(shí)模型的平臺(tái),讓知識(shí)提供者能便捷分享最新研究成果;提供通用的模型API(application programming interface,應(yīng)用程序接口)接口,軟件工程師不需要掌握醫(yī)學(xué)知識(shí)即可對(duì)模型進(jìn)行組合與部署,研發(fā)符合定制化業(yè)務(wù)流程的應(yīng)用;患者可通過已有應(yīng)用進(jìn)行健康狀況自評(píng)與疾病風(fēng)險(xiǎn)預(yù)測(cè),醫(yī)護(hù)人員可以使用應(yīng)用輔助診療與科研。通過與北京大學(xué)醫(yī)學(xué)部、北京大學(xué)第一醫(yī)院、密歇根大學(xué)等多家醫(yī)療機(jī)構(gòu)與國(guó)內(nèi)外院校開展深度合作,推動(dòng)了學(xué)習(xí)型智慧健康體系在中國(guó)的落地發(fā)展。
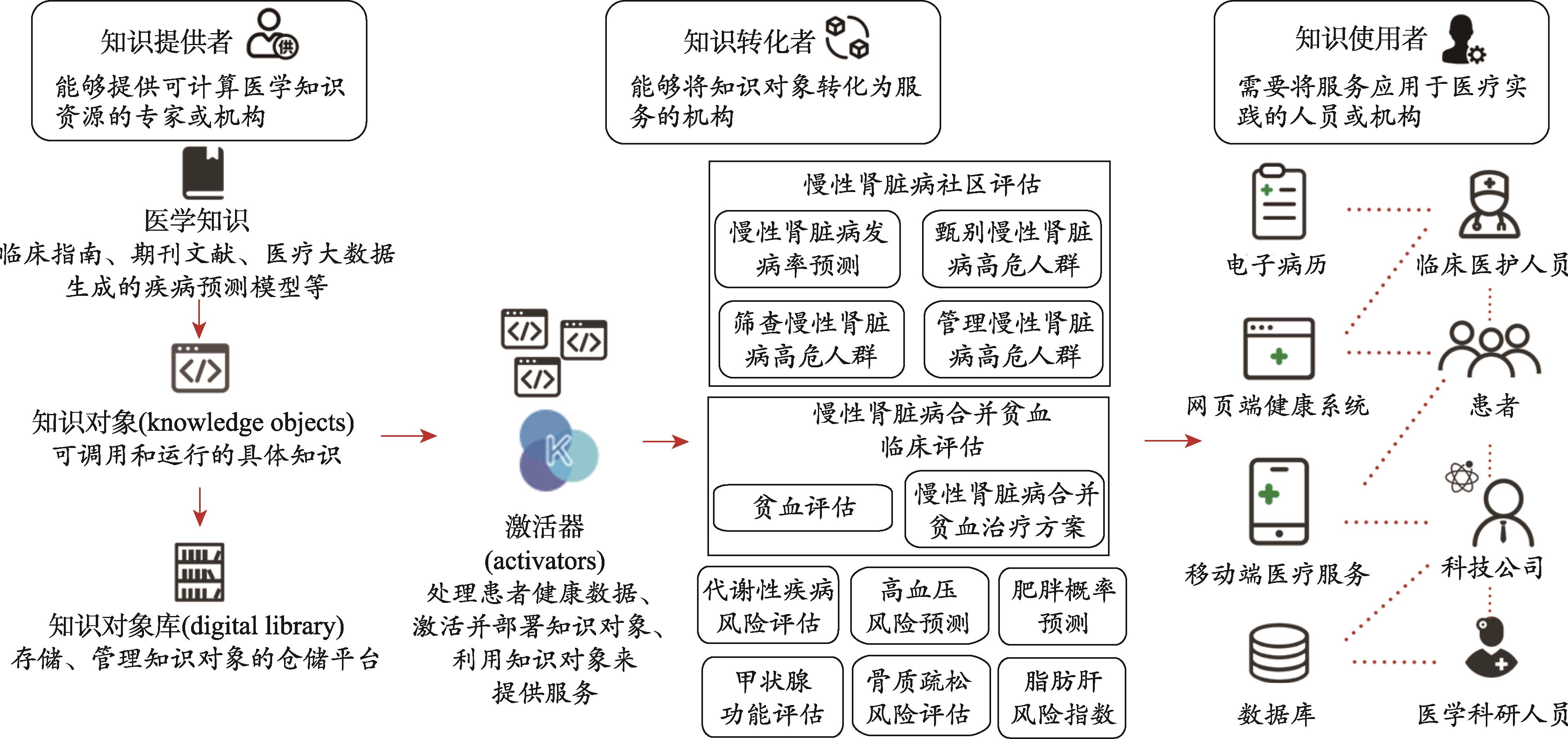
圖2 K-Grid-China可計(jì)算醫(yī)學(xué)知識(shí)智能應(yīng)用平臺(tái)示意圖
其主要功能是把原先需要醫(yī)護(hù)人員、醫(yī)療領(lǐng)域決策者或者醫(yī)學(xué)科研人員認(rèn)真閱讀、深入理解才能具體掌握的醫(yī)學(xué)知識(shí),轉(zhuǎn)變?yōu)榭捎?jì)算的醫(yī)學(xué)知識(shí)對(duì)象,以供各類醫(yī)學(xué)應(yīng)用大規(guī)模、并行、且實(shí)時(shí)地調(diào)用運(yùn)行。該平臺(tái)的核心組件主要包含知識(shí)對(duì)象、知識(shí)對(duì)象庫(kù)、知識(shí)對(duì)象激活器以及服務(wù)四個(gè)部分(
圖2
)。
(1)知識(shí)對(duì)象(knowledge objects)。知識(shí)對(duì)象是經(jīng)編程封裝的模塊化、計(jì)算機(jī)可識(shí)別、可處理執(zhí)行的知識(shí)模塊。其來(lái)源可以是臨床指南(guideline)、期刊文獻(xiàn)以及數(shù)據(jù)驅(qū)動(dòng)的疾病預(yù)測(cè)模型等。知識(shí)對(duì)象包含程序語(yǔ)言所組成的核心知識(shí)載體(knowledge payload)、用于與外界溝通的知識(shí)對(duì)象元數(shù)據(jù)(metadata)、該知識(shí)對(duì)象部署及相關(guān)服務(wù)的詳細(xì)說(shuō)明(specification)。
(2)知識(shí)對(duì)象庫(kù)(digital library)。知識(shí)對(duì)象庫(kù)用來(lái)儲(chǔ)存與管理知識(shí)對(duì)象。一個(gè)知識(shí)網(wǎng)格平臺(tái)可以包含多個(gè)知識(shí)對(duì)象庫(kù),知識(shí)對(duì)象庫(kù)之間相互關(guān)聯(lián),知識(shí)對(duì)象庫(kù)的基礎(chǔ)為一個(gè)網(wǎng)絡(luò)服務(wù)器(web server),加上對(duì)象檢索服務(wù)。
(3)知識(shí)對(duì)象激活器(activators)。知識(shí)對(duì)象激活器是一個(gè)用來(lái)處理患者健康數(shù)據(jù)、激活并部署知識(shí)對(duì)象、利用知識(shí)對(duì)象來(lái)提供服務(wù)的工具。激活器提供可平行擴(kuò)展的工具來(lái)讓知識(shí)對(duì)象基于真實(shí)世界的患者數(shù)據(jù)進(jìn)行計(jì)算推理,并給出運(yùn)行結(jié)果。理想上激活器可以執(zhí)行以不同語(yǔ)言所編程封裝的知識(shí)載體,可將知識(shí)載體提供給其他應(yīng)用程序,也可讓某一知識(shí)載體本身提供服務(wù)。
(4)服務(wù)(services)。核心功能在于鏈接醫(yī)學(xué)應(yīng)用與知識(shí)對(duì)象,利用外界應(yīng)用的輸入數(shù)據(jù)激活相關(guān)的知識(shí)對(duì)象,并把運(yùn)行結(jié)果反饋給外界應(yīng)用。
知識(shí)網(wǎng)格平臺(tái)與各個(gè)來(lái)源不同、類型相異的醫(yī)學(xué)知識(shí)相比較,就如共同的橋梁和獨(dú)立的小船,知識(shí)網(wǎng)格平臺(tái)為各種醫(yī)學(xué)知識(shí)提供了一個(gè)通用的平臺(tái)工具,讓各類醫(yī)學(xué)知識(shí)能夠通過該平臺(tái)以一個(gè)通用的標(biāo)準(zhǔn)和模式為各類醫(yī)學(xué)應(yīng)用所調(diào)用,以期為學(xué)習(xí)型智慧健康醫(yī)療體系中知識(shí)到實(shí)踐一環(huán)提供基礎(chǔ)架構(gòu)。
在該路徑中,推進(jìn)可計(jì)算的醫(yī)學(xué)知識(shí)研發(fā)與應(yīng)用還面臨著若干挑戰(zhàn)。一是將可計(jì)算的知識(shí)對(duì)象,例如,疾病預(yù)測(cè)模型應(yīng)用于不同的電子病歷系統(tǒng)涉及的標(biāo)準(zhǔn)和互操作性問題;二是需要更好地追蹤和評(píng)估可計(jì)算醫(yī)學(xué)知識(shí)對(duì)患者診療結(jié)果的影響;三是如何將目前針對(duì)單一病種的可計(jì)算醫(yī)學(xué)知識(shí)實(shí)現(xiàn)方法和手段拓展到針對(duì)共病的醫(yī)學(xué)知識(shí)
等
[
34
]。
4.2 路徑二:從非結(jié)構(gòu)化文本中生成的可計(jì)算醫(yī)學(xué)知識(shí)
從文本信息中提取知識(shí),開展知識(shí)計(jì)算一直是情報(bào)學(xué)的前沿問題,其核心在于找到合適的知識(shí)單元,即要解決什么是知識(shí)以及用什么來(lái)表示知識(shí)。現(xiàn)有研究表明,受計(jì)算機(jī)科學(xué)領(lǐng)域啟發(fā),以“實(shí)體-關(guān)系-實(shí)體”和“概念-屬性-值”三元組作為知識(shí)計(jì)算單元,具有理論上的合理性以及數(shù)據(jù)實(shí)現(xiàn)的可行
性
[
35
]。數(shù)字時(shí)代,文本大數(shù)據(jù)中隱藏著大量醫(yī)學(xué)知識(shí),去除醫(yī)學(xué)文本冗余部分并提取結(jié)構(gòu)化知識(shí)單元是解決信息超載問題、實(shí)現(xiàn)大規(guī)模知識(shí)計(jì)算的關(guān)鍵。但仍有兩個(gè)科學(xué)問題需要解決。一是如何既完整又最小化(不可再分)地表示一個(gè)獨(dú)立的醫(yī)學(xué)知識(shí)單元,即如何在三元組及其邏輯組合形成的知識(shí)圖譜中,找到一個(gè)最小子圖,作為可計(jì)算醫(yī)學(xué)知識(shí)的基本單元,對(duì)其利用計(jì)算機(jī)語(yǔ)言進(jìn)行編程實(shí)現(xiàn),通過計(jì)算機(jī)程序?qū)崿F(xiàn)與醫(yī)療數(shù)據(jù)之間的自動(dòng)化對(duì)話;二是鑒于醫(yī)學(xué)知識(shí)的個(gè)體化和不確定性特征,需要明確醫(yī)學(xué)知識(shí)單元成立的依賴條件和證據(jù)來(lái)源,同時(shí)兼顧醫(yī)學(xué)知識(shí)表示的結(jié)構(gòu)化、完整性和不可再分性,才能將人讀的知識(shí)格式盡可能“無(wú)丟失”和“無(wú)冗余”地轉(zhuǎn)化為機(jī)器可讀且可執(zhí)行的知識(shí)格式。
以美國(guó)密歇根大學(xué)K-Grid原型為基礎(chǔ),參考荷蘭萊頓大學(xué)納米出版模型和知識(shí)子圖(knowlet)模型,本文提出從非結(jié)構(gòu)化文本中生成可計(jì)算醫(yī)學(xué)知識(shí)的語(yǔ)義表示模型(
圖3
)和主要實(shí)現(xiàn)路徑(
圖4
)。該模型兼顧醫(yī)學(xué)知識(shí)結(jié)構(gòu)化和可執(zhí)行兩個(gè)核心要點(diǎn),考慮將置信度作為醫(yī)學(xué)知識(shí)執(zhí)行和應(yīng)用的必要條件,以“可編碼知識(shí)單元+置信度+可追蹤的證據(jù)來(lái)源”為基本組件,每個(gè)組件均以資源描述框架(resource description framework,RDF)格式進(jìn)行描述。為實(shí)現(xiàn)知識(shí)之間的互操作,對(duì)每個(gè)可編碼知識(shí)單元分配一個(gè)可信任的統(tǒng)一資源標(biāo)識(shí)符。該模型將“知識(shí)單元”及其背后的數(shù)據(jù)和證據(jù)鏈接起來(lái)。
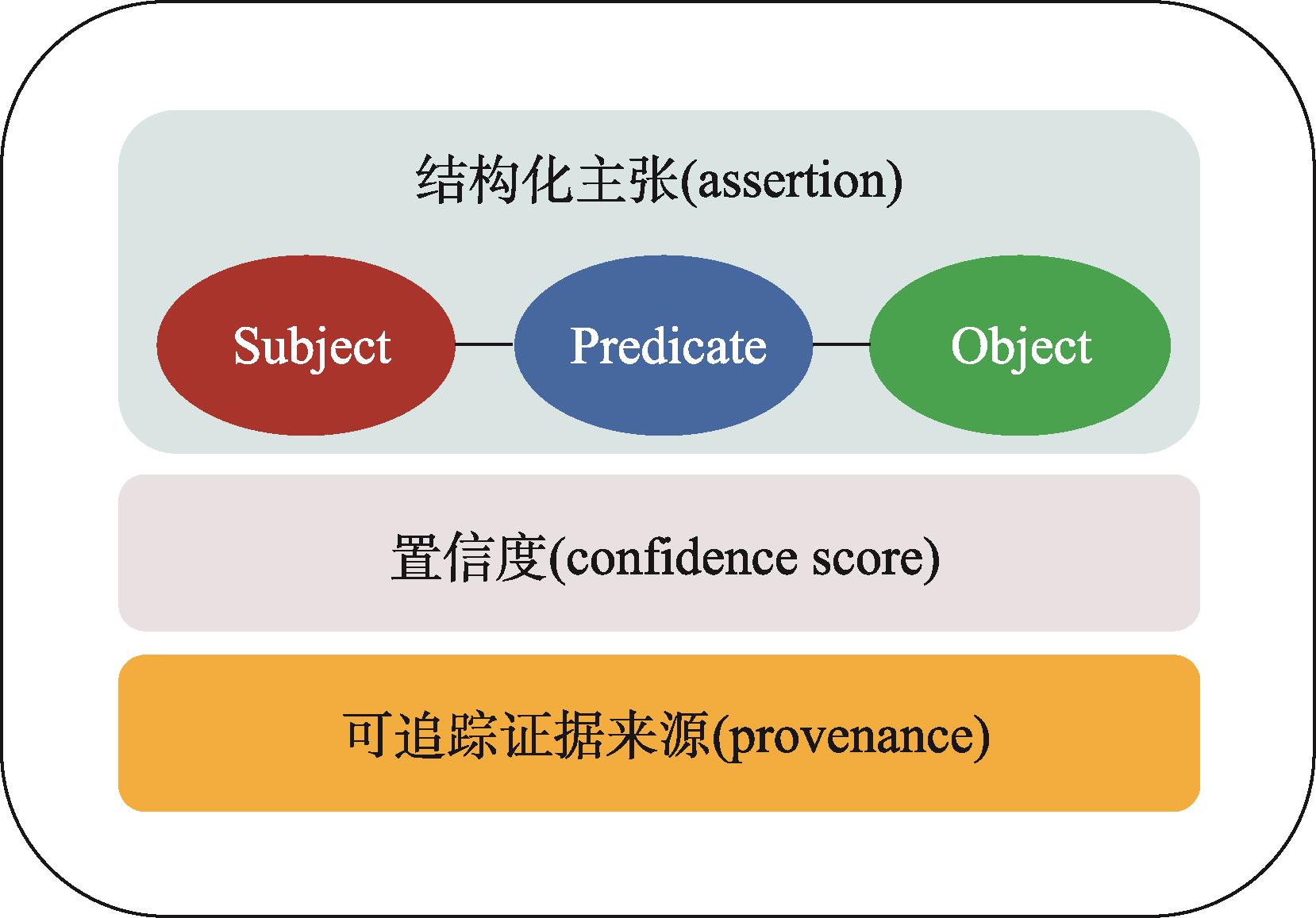
圖3 從非結(jié)構(gòu)化文本中生成的可計(jì)算醫(yī)學(xué)知識(shí)的語(yǔ)義表示模型
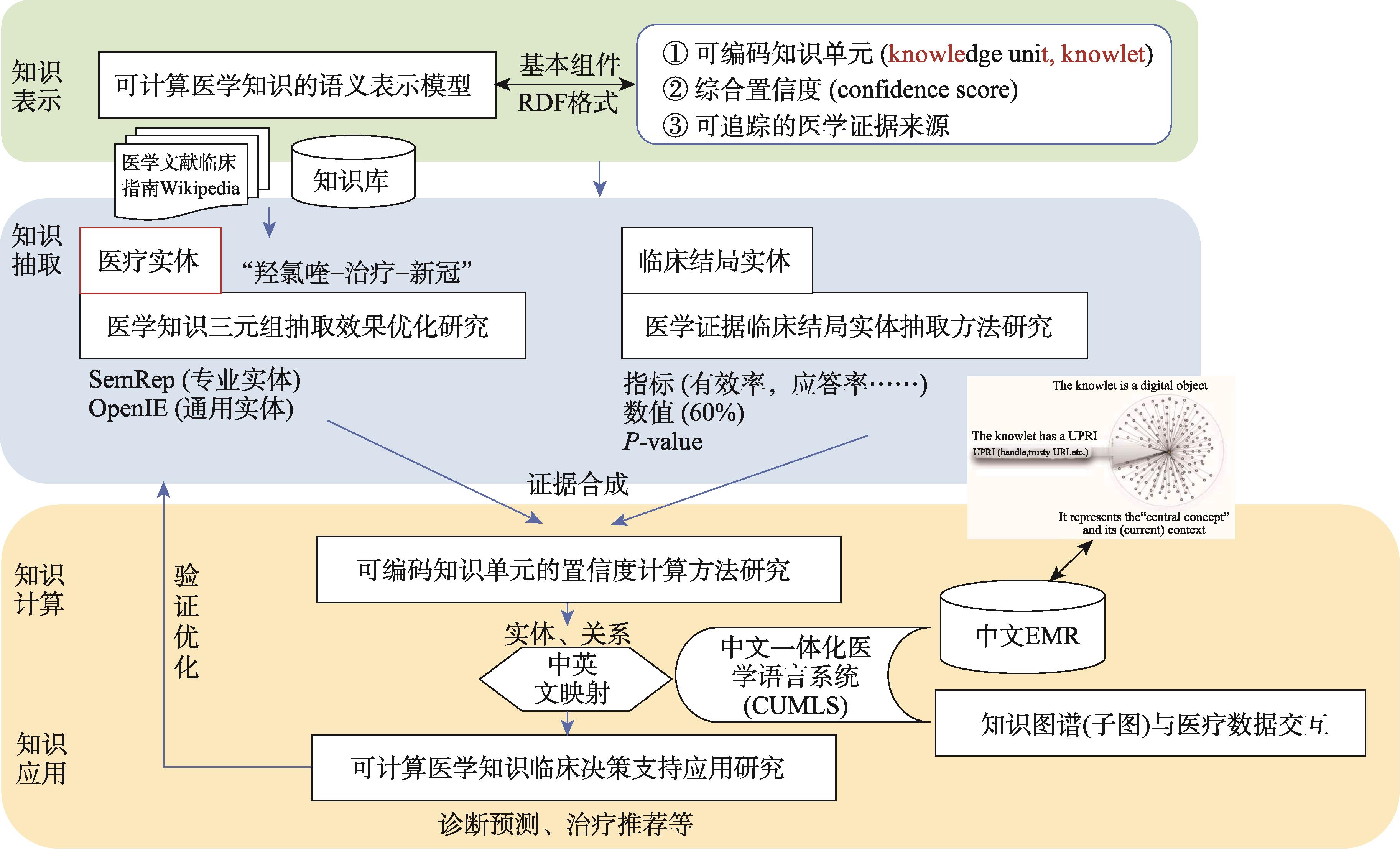
圖4 源于非結(jié)構(gòu)化文本的可計(jì)算醫(yī)學(xué)知識(shí)流程圖
該模型的關(guān)鍵要素主要包括三個(gè)方面。
(1)知識(shí)的結(jié)構(gòu)化問題。采用較為成熟的英文醫(yī)學(xué)自然語(yǔ)言處理工具和中英文醫(yī)學(xué)術(shù)語(yǔ)映射體系,解決中文醫(yī)學(xué)自然語(yǔ)言處理和三元組抽取問題,形成以主語(yǔ)-謂語(yǔ)-賓語(yǔ)三元組形式表示的結(jié)構(gòu)化主張。針對(duì)英文自然語(yǔ)言表述的醫(yī)學(xué)文獻(xiàn)、臨床指南、醫(yī)學(xué)百科和現(xiàn)有醫(yī)學(xué)知識(shí)庫(kù)等,利用一體化醫(yī)學(xué)語(yǔ)言系統(tǒng)(UMLS),優(yōu)化基于SemRep抽取的臨床相關(guān)“概念-關(guān)系-概念”三元組;對(duì)于召回率低的問題,考慮增加利用通用信息抽取工具,如OpenIE抽取“實(shí)體-屬性-值”三元組。同時(shí),需要開展醫(yī)學(xué)證據(jù)、結(jié)局指標(biāo)與數(shù)值抽取,內(nèi)容包括臨床結(jié)局指標(biāo)(如有效率、應(yīng)答率等)、值及P-value。例如,從自然語(yǔ)言文本“2019年我國(guó)心血管疾病導(dǎo)致死亡人數(shù)約460萬(wàn),占全部死亡的43%”中可抽取出:①三元組:“心血管疾病-死亡占比-43%”;②依賴條件:中國(guó)人群;③證據(jù)來(lái)源:2019年全球疾病負(fù)擔(dān)報(bào)告(the global burden of disease study 2019,GBD 2019)。同時(shí),探索基于臨床試驗(yàn)注冊(cè)平臺(tái)數(shù)據(jù)開展證據(jù)合成的方法研究,以美國(guó)Clinicaltrials.gov、中國(guó)臨床試驗(yàn)注冊(cè)平臺(tái)等為基礎(chǔ),利用其相對(duì)結(jié)構(gòu)化的數(shù)據(jù),自動(dòng)生成“患者-干預(yù)-對(duì)照-結(jié)局”(population-interventions-comparisons-outcomes,PICO),對(duì)于注冊(cè)平臺(tái)上未報(bào)告結(jié)果的試驗(yàn),通過計(jì)算機(jī)軟件工具獲取書目數(shù)據(jù)庫(kù)(如PubMed)或網(wǎng)絡(luò)(如權(quán)威會(huì)議報(bào)道)報(bào)告結(jié)果。
(2)知識(shí)的置信度問題。針對(duì)現(xiàn)有的臨床治療類知識(shí)圖譜中三元組因缺乏置信度(confidence score)導(dǎo)致在真實(shí)世界臨床決策難以落地的瓶頸,需要對(duì)醫(yī)學(xué)知識(shí)三元組的置信度水平進(jìn)行計(jì)算,但總體的置信度水平離不開每個(gè)證據(jù)的臨床結(jié)局。根據(jù)證據(jù)推理(evidential reasoning)理論,把不同的臨床證據(jù)的置信度進(jìn)行合成,可計(jì)算得到該三元組的綜合置信度得分。通過舍棄置信度較低的知識(shí),或找到置信度較低知識(shí)的條件來(lái)保障知識(shí)圖譜中三元組的質(zhì)量。
(3)知識(shí)的臨床決策支持應(yīng)用。基于中文一體化醫(yī)學(xué)語(yǔ)言系統(tǒng)(Chinese unified medical language system,CUMLS
)
[
36
]、國(guó)家衛(wèi)生健康委員會(huì)陸續(xù)發(fā)布的中文醫(yī)學(xué)術(shù)語(yǔ)表等,對(duì)構(gòu)建的醫(yī)學(xué)知識(shí)圖譜中各三元組中的概念和關(guān)系進(jìn)行中英文映射,轉(zhuǎn)化為中文醫(yī)學(xué)知識(shí)圖譜三元組。探索實(shí)現(xiàn)醫(yī)學(xué)知識(shí)“可執(zhí)行”的機(jī)制,將醫(yī)學(xué)知識(shí)圖譜的子圖作為知識(shí)單元進(jìn)行計(jì)算機(jī)語(yǔ)言編碼,并開發(fā)與真實(shí)世界電子病歷中數(shù)據(jù)對(duì)話的接口。基于帶有置信度的知識(shí)三元組,通過計(jì)算機(jī)編程封裝轉(zhuǎn)化為可計(jì)算知識(shí)對(duì)象以輔助臨床決策,如診斷預(yù)測(cè)、治療推薦等。通過在臨床工作流程中嵌入可計(jì)算知識(shí)對(duì)象、開發(fā)可計(jì)算知識(shí)和患者數(shù)據(jù)之間的對(duì)話機(jī)制,解決從知識(shí)到實(shí)踐,從實(shí)踐再到數(shù)據(jù)的循環(huán)式學(xué)習(xí),解決醫(yī)學(xué)知識(shí)圖譜在真實(shí)場(chǎng)景中落地應(yīng)用問題。
對(duì)于從非結(jié)構(gòu)化文本中抽取可計(jì)算醫(yī)學(xué)知識(shí),結(jié)構(gòu)化和可執(zhí)行同樣是其兩個(gè)關(guān)鍵要素,也是兩個(gè)重要目標(biāo)。其中,結(jié)構(gòu)化是指從非結(jié)構(gòu)化醫(yī)學(xué)文本中生成結(jié)構(gòu)化的知識(shí),并構(gòu)建適宜的表示和存儲(chǔ)模型,實(shí)現(xiàn)大規(guī)模存取;可執(zhí)行是指能與電子病歷(EMR)數(shù)據(jù)進(jìn)行交互,并提供決策支持,實(shí)現(xiàn)大規(guī)模使用。在知識(shí)圖譜三元組的基礎(chǔ)上,提出增加通過證據(jù)推理融合計(jì)算總體置信度水平的思路,解決的知識(shí)應(yīng)用的關(guān)鍵瓶頸——不確定性。最終實(shí)現(xiàn)“從數(shù)據(jù)到知識(shí)、從知識(shí)到實(shí)踐、從實(shí)踐再到數(shù)據(jù)”的循環(huán)式學(xué)習(xí),促進(jìn)醫(yī)學(xué)知識(shí)快速服務(wù)于臨床實(shí)踐。
5.1 可計(jì)算醫(yī)學(xué)知識(shí)的理論概念為深化情報(bào)學(xué)研究提供了新的范式
本文所討論的“可計(jì)算醫(yī)學(xué)知識(shí)”,均來(lái)源于醫(yī)學(xué)文獻(xiàn)、臨床指南等科學(xué)出版物,其中既涉及邏輯化的知識(shí)對(duì)象,又涉及結(jié)構(gòu)化的知識(shí)單元。對(duì)科學(xué)出版物的分析挖掘本身就是情報(bào)學(xué)的“看家本領(lǐng)”。但本文的研究重點(diǎn)并非對(duì)科學(xué)出版物外部屬性特征的分析挖掘,而是對(duì)其中蘊(yùn)含的知識(shí)單元或知識(shí)對(duì)象的分析挖掘,這也是促進(jìn)情報(bào)學(xué)向深層次發(fā)展的需要,正如我國(guó)情報(bào)學(xué)學(xué)者馬費(fèi)成教授曾指出,從物理層次的文獻(xiàn)單元向認(rèn)知層次的知識(shí)單元轉(zhuǎn)換是情報(bào)學(xué)取得突破性發(fā)展需要解決的關(guān)鍵問題。本文所涉內(nèi)容是通過醫(yī)學(xué)信息學(xué)或循證醫(yī)學(xué)的智能化實(shí)現(xiàn)技術(shù)作為手段或途徑,來(lái)討論如何把科學(xué)出版物中的知識(shí)主張或知識(shí)對(duì)象,以合適的形式抽取出來(lái),并通過編程封裝,形成可計(jì)算的知識(shí),即計(jì)算機(jī)可直接執(zhí)行的知識(shí),以促進(jìn)知識(shí)的大規(guī)模應(yīng)用,打通“data to knowledge”(D2K)和“knowledge to practice”(K2P)的鴻溝。
從科學(xué)出版物中抽取出知識(shí)單元或知識(shí)對(duì)象的過程,本身也是一個(gè)信息處理和情報(bào)提取的過程。但是,到底什么是知識(shí)單元或知識(shí)對(duì)象,需要明確其定義并構(gòu)建合適的模型,即對(duì)“可計(jì)算化”進(jìn)行建模。本文提出的兩條實(shí)現(xiàn)路徑,實(shí)際上分別對(duì)應(yīng)了知識(shí)對(duì)象和知識(shí)單元。
受OMAHA白皮書《促進(jìn)醫(yī)學(xué)知識(shí)價(jià)值開發(fā):臨床指南的計(jì)算機(jī)化》(2019
)
[
37
]的啟發(fā),本文認(rèn)為,知識(shí)對(duì)象的抽取和封裝過程是基于知識(shí)的建模;知識(shí)單元的抽取和封裝過程是基于文檔的建模。前者側(cè)重知識(shí)的內(nèi)在邏輯,后者側(cè)重知識(shí)的表示形式。
(1)基于文檔的模型。以科學(xué)出版物文檔本身為中心,將其中以文本表示的知識(shí)主張(knowledge claims)轉(zhuǎn)換為計(jì)算機(jī)可以理解的文檔形式,例如,以三元組為主要形式的知識(shí)單元,強(qiáng)調(diào)知識(shí)主張的結(jié)構(gòu)化。這種模型結(jié)構(gòu)清晰、表示方法簡(jiǎn)單易懂、不需要特殊執(zhí)行框架,可通過圖數(shù)據(jù)庫(kù)進(jìn)行存儲(chǔ)和查詢,即使不懂編程知識(shí)的用戶(如醫(yī)學(xué)研究者、醫(yī)生等)也可使用,其通用性較強(qiáng)。但由于其計(jì)算機(jī)化的程度只到文檔層面,就導(dǎo)致了其對(duì)科學(xué)出版物中知識(shí)主張及其背后的邏輯論證過程的解構(gòu)程度較淺,無(wú)法實(shí)現(xiàn)知識(shí)主張中復(fù)雜邏輯知識(shí)的表達(dá),因此,其在決策支持(如臨床輔助決策支持)層面的應(yīng)用較淺,復(fù)雜知識(shí)的表達(dá)還得依賴基于知識(shí)的模型。
(2)基于知識(shí)的模型。以科學(xué)出版物中的知識(shí)為核心,將其中的知識(shí)對(duì)象以規(guī)則、決策樹或者任務(wù)網(wǎng)絡(luò)的形式進(jìn)行邏輯的呈現(xiàn),強(qiáng)調(diào)知識(shí)的邏輯表示形式,采用專門的格式將知識(shí)表示為一種形式化、計(jì)算機(jī)可讀的形式,并且將不同知識(shí)融合形成一套知識(shí)庫(kù),用于臨床輔助決策系統(tǒng),并強(qiáng)調(diào)與電子病歷系統(tǒng)的結(jié)合。同時(shí),強(qiáng)調(diào)在不同機(jī)構(gòu)和不同執(zhí)行平臺(tái)間的知識(shí)共享,故標(biāo)準(zhǔn)化的醫(yī)學(xué)術(shù)語(yǔ),如SNOMED CT(systematized nomenclature of medicine clinical terms)、UMLS和MeSH(medical subject headings)應(yīng)用非常普遍。由于對(duì)醫(yī)學(xué)知識(shí)的解構(gòu)較深,這類模型普遍需要臨床的醫(yī)務(wù)工作者或者指南的撰寫者與編程人員一起開發(fā),才能更好地理解和表達(dá)醫(yī)學(xué)文獻(xiàn)與臨床指南中所包含的知識(shí)對(duì)象。
5.2 可計(jì)算醫(yī)學(xué)知識(shí)在促進(jìn)知識(shí)轉(zhuǎn)化、知識(shí)發(fā)現(xiàn)和循證決策中的應(yīng)用場(chǎng)景
本文結(jié)合與情報(bào)學(xué)密切相關(guān)的科學(xué)哲學(xué)、決策科學(xué)等以“知識(shí)”為關(guān)注對(duì)象的領(lǐng)域的最新觀點(diǎn)和進(jìn)展,從學(xué)科交叉的角度,討論可計(jì)算醫(yī)學(xué)知識(shí)在促進(jìn)知識(shí)轉(zhuǎn)化、知識(shí)發(fā)現(xiàn)和循證決策的可靠性方面的具體應(yīng)用場(chǎng)景。
(1)促進(jìn)從知識(shí)到實(shí)踐。目前,科學(xué)知識(shí)基本以文本格式發(fā)布,不利于用戶使用。科學(xué)出版物是知識(shí)載體,從中抽取知識(shí)單元或知識(shí)對(duì)象,并封裝成軟件代碼,這是可計(jì)算知識(shí)的基本概念和路徑。與其他學(xué)科領(lǐng)域相比,醫(yī)學(xué)領(lǐng)域和信息學(xué)的交叉研究(如醫(yī)學(xué)信息學(xué)、健康信息學(xué))的技術(shù)進(jìn)展較快,需求也更為迫切,尤其是醫(yī)療實(shí)踐需要跟上醫(yī)學(xué)知識(shí)的快速增長(zhǎng)和更新,需要將醫(yī)學(xué)知識(shí)快速轉(zhuǎn)化為醫(yī)療實(shí)踐,而將人讀的醫(yī)學(xué)知識(shí)轉(zhuǎn)化為機(jī)器可讀、可執(zhí)行的醫(yī)學(xué)知識(shí)是促進(jìn)“知識(shí)到實(shí)踐”的有效途徑。
(2)面向知識(shí)發(fā)現(xiàn)的知識(shí)管理。將科學(xué)知識(shí)儲(chǔ)存在論文里,很難將所有的發(fā)現(xiàn)整合起來(lái)。學(xué)界認(rèn)為,以數(shù)據(jù)為中心的科學(xué)標(biāo)志著數(shù)據(jù)必須從論文限制中“解放”出來(lái),并存儲(chǔ)在云端,以看到更大、更具全局性的畫面。理想情況下,所有的科學(xué)出版物都應(yīng)該是計(jì)算機(jī)可讀的,這樣計(jì)算機(jī)就可以檢測(cè)出人類無(wú)法識(shí)別的模
式
[
38
]。最近,挪威學(xué)者在《計(jì)算時(shí)代“可解釋的、可計(jì)算的、可管理的”的科學(xué)知識(shí)》一文中,提出將知識(shí)視為可計(jì)算對(duì)象的觀
點(diǎn)[
39
],認(rèn)為計(jì)算賦能(可計(jì)算)的知識(shí)管理實(shí)踐提供了獲取新的一階科學(xué)知識(shí)的二階科學(xué)研究方法,并提出了兩個(gè)基本的知識(shí)概念:①知識(shí)被認(rèn)為是在已發(fā)表的科學(xué)文本中顯性表達(dá)的事實(shí)和信息;②知識(shí)被認(rèn)為是通過適當(dāng)?shù)呐缮鷶?shù)據(jù)(derived data)和元數(shù)據(jù)來(lái)實(shí)現(xiàn)計(jì)算的。他們將可計(jì)算的知識(shí)管理(computable knowledge management)定義為:在科學(xué)出版物(如PubMed)和知識(shí)庫(kù)(如GenBank)等一階知識(shí)的基礎(chǔ)上開展二階科學(xué)研究,生成新的一階知識(shí)的過程。本文認(rèn)為,這一概念與基于文獻(xiàn)的知識(shí)發(fā)現(xiàn)(literature-based discovery)是相似的,即把零散的、不相關(guān)的信息進(jìn)行整合,揭示出新的、有希望的、令人驚訝的研究方向,或者提供潛在的變革性或突破性的見
解[
40
]。計(jì)算科學(xué)家以從文獻(xiàn)和數(shù)據(jù)庫(kù)中提取的知識(shí)為基礎(chǔ),對(duì)其進(jìn)行計(jì)算處理,從而挖掘出可以由實(shí)驗(yàn)科學(xué)家在實(shí)驗(yàn)中得到檢驗(yàn)的新假設(shè)。實(shí)驗(yàn)科學(xué)家和計(jì)算科學(xué)家之間的合作已成為科學(xué)知識(shí)發(fā)現(xiàn)的新趨勢(shì)。
目前,知識(shí)管理主要依賴于客觀認(rèn)識(shí)論,即將知識(shí)視為客觀的、物理的、可完全可解釋的,而忽視了知識(shí)的不完整性、不確定性程度及其上下文背景,如其依賴的條件。要真正實(shí)現(xiàn)從現(xiàn)有知識(shí)大數(shù)據(jù)中再次發(fā)現(xiàn)新的知識(shí),就不應(yīng)僅關(guān)注結(jié)構(gòu)化的知識(shí)單元(knowledge unit),還要關(guān)注知識(shí)背景(knowledge context)。以實(shí)踐為基礎(chǔ)的認(rèn)識(shí)論挑戰(zhàn)了科學(xué)知識(shí)可以完全解釋和編碼的假設(shè),其認(rèn)為開發(fā)知識(shí)管理工具以及據(jù)此做出決策和判斷需要考慮科學(xué)知識(shí)固有的模糊性、不確定性;而且科學(xué)知識(shí)是多維的,既有具體性又有抽象性,既有隱性又有顯性,既有集體性又有個(gè)體性,既有發(fā)展性又有靜態(tài)性。認(rèn)識(shí)到知識(shí)表達(dá)的多樣性、模糊性、不確定性和不一致性,才能更高效地發(fā)現(xiàn)新的知識(shí)。將知識(shí)的動(dòng)態(tài)性、不確定性、具象化和爭(zhēng)議性納入計(jì)算過程,是確保知識(shí)發(fā)現(xiàn)的有效性和可靠性的關(guān)鍵因素。因此,本文在知識(shí)圖譜三元組的基礎(chǔ)上,提出增加通過證據(jù)推理融合計(jì)算總體置信度水平的思路,解決的知識(shí)應(yīng)用的關(guān)鍵瓶頸——不確定性,以打通知識(shí)和實(shí)踐之間的橋梁。
(3)循證決策。循證決策(evidence-based policy-making)是借鑒循證醫(yī)學(xué)而發(fā)展出來(lái)的一套決策理論,認(rèn)為政策和決策制定也應(yīng)吸收和使用最新的科學(xué)證據(jù),同時(shí),將社會(huì)經(jīng)驗(yàn)和價(jià)值判斷結(jié)合起來(lái),尤其是在突發(fā)事件中,做出最佳決策,如新冠肺炎疫情的防控和治
療
[
41
]。但在政策和實(shí)踐中執(zhí)行循證決策時(shí),需要克服以下障
礙[
42
]:①錯(cuò)失機(jī)會(huì)窗。如果在需要制定關(guān)鍵決策時(shí)沒有所需要的證據(jù)(或沒有資源/基礎(chǔ)設(shè)施),那么就會(huì)失去循證干預(yù)的機(jī)會(huì)。②知識(shí)缺口與不確定性。③有爭(zhēng)議、無(wú)關(guān)的和相互矛盾的證據(jù),這時(shí)不清楚遵循哪一條路徑,會(huì)增加制定不正確或非循證決策的風(fēng)險(xiǎn)。而第二條和第三條障礙都涉及知識(shí)的不完備性和不確定性,促進(jìn)本文對(duì)DIKW(data, information, knowledge, wisdom)模型的再次理解,尤其是關(guān)于如何從知識(shí)到智慧這一環(huán)節(jié)。從數(shù)據(jù)到信息,再到知識(shí),解釋的是“when/where/who/what”和“how/why”的問題。而從知識(shí)到智慧,解決的是“如何在不完備和不確定條件下中做出最佳決策”的問題。醫(yī)學(xué)知識(shí)的不完備性和不確定性是客觀存在的,是醫(yī)學(xué)決策經(jīng)常面臨的現(xiàn)實(shí)環(huán)境和需要考慮的重要因素。從情報(bào)學(xué)的角度對(duì)醫(yī)學(xué)知識(shí)不確定性進(jìn)行測(cè)度,通過可計(jì)算的知識(shí)實(shí)現(xiàn)路徑,及時(shí)挖掘出有爭(zhēng)議的和相互矛盾的科學(xué)證據(jù),可為循證決策提供重要的參考和依據(jù)。過去針對(duì)政府決策需求的情報(bào)學(xué)研究和服務(wù)可能多側(cè)重提供確定性的信息和知識(shí),特別是已證實(shí)或證偽的并有大量依據(jù)來(lái)支持。而識(shí)別知識(shí)缺口并通過情報(bào)學(xué)研究,特別是基于文獻(xiàn)的知識(shí)發(fā)現(xiàn),彌補(bǔ)這些知識(shí)缺口,以及測(cè)度并甄別出不確定性的知識(shí)及其背后的原因和條件,對(duì)于循證決策至關(guān)重要。
參 考 文 獻(xiàn)
1
葉鷹, 馬費(fèi)成. 數(shù)據(jù)科學(xué)興起及其與信息科學(xué)的關(guān)聯(lián)[J]. 情報(bào)學(xué)報(bào), 2015, 34(6): 575-580. [百度學(xué)術(shù)]
2
Zhu L S, Zheng W J. Informatics, data science, and artificial intelligence[J]. JAMA, 2018, 320(11): 1103-1104. [百度學(xué)術(shù)]
3
Fortunato S, Bergstrom C T, B?rner K, et al. Science of science[J]. Science, 2018, 359(6379): eaao0185. [百度學(xué)術(shù)]
4
Milojevi? S. Quantifying the cognitive extent of science[J]. Journal of Informetrics, 2015, 9(4): 962-973. [百度學(xué)術(shù)]
5
馬費(fèi)成. 情報(bào)學(xué)的進(jìn)展與深化[J]. 情報(bào)學(xué)報(bào), 1996, 15(5): 22-28. [百度學(xué)術(shù)]
6
文庭孝, 羅賢春, 劉曉英, 等. 知識(shí)單元研究述評(píng)[J]. 中國(guó)圖書館學(xué)報(bào), 2011, 37(5): 75-86. [百度學(xué)術(shù)]
7
Friedman C P, Flynn A J. Computable knowledge: an imperative for Learning Health Systems[J]. Learning Health Systems, 2019, 3(4): e10203. [百度學(xué)術(shù)]
8
Williams M, Richesson R L, Bray B E, et al. Summary of third annual MCBK public meeting: mobilizing computable biomedical knowledge—accelerating the second knowledge revolution[J]. Learning Health Systems, 2021, 5(1): e10255. [百度學(xué)術(shù)]
9
Wyatt J, Scott P. Computable knowledge is the enemy of disease[J]. BMJ Health & Care Informatics, 2020, 27(2): e100200.[百度學(xué)術(shù)]
10
Kilicoglu H, Rosemblat G, Fiszman M, et al. Broad-coverage biomedical relation extraction with SemRep[J]. BMC Bioinformatics, 2020, 21(1): 188. [百度學(xué)術(shù)]
11
索傳軍, 蓋雙雙. 知識(shí)元的內(nèi)涵、結(jié)構(gòu)與描述模型研究[J]. 中國(guó)圖書館學(xué)報(bào), 2018, 44(4): 54-72. [百度學(xué)術(shù)]
12
Flynn A J, Friedman C P, Boisvert P, et al. The Knowledge Object Reference Ontology (KORO): a formalism to support management and sharing of computable biomedical knowledge for learning health systems[J]. Learning Health Systems, 2018, 2(2): e10054. [百度學(xué)術(shù)]
13
Yang X L, Li J X, Hu D S, et al. Predicting the 10-year risks of atherosclerotic cardiovascular disease in Chinese population: the China-PAR project (prediction for ASCVD risk in China)[J]. Circulation, 2016, 134(19): 1430-1440. [百度學(xué)術(shù)]
14
Callahan T J, Tripodi I J, Pielke-Lombardo H, et al. Knowledge-based biomedical data science[J]. Annual Review of Biomedical Data Science, 2020, 3: 23-41. [百度學(xué)術(shù)]
15
Zhang D C, He D Q. Enhancing clinical decision support systems with public knowledge bases[J]. Data and Information Management, 2017, 1(1): 49-60. [百度學(xué)術(shù)]
16
覃露, 徐曉巍, 丁玲玲, 等. 面向決策支持的臨床指南知識(shí)表示方法研究[J]. 中華醫(yī)學(xué)圖書情報(bào)雜志, 2020, 29(2): 1-8. [百度學(xué)術(shù)]
17
朱超宇, 劉雷. 基于知識(shí)圖譜的醫(yī)學(xué)決策支持應(yīng)用綜述[J]. 數(shù)據(jù)分析與知識(shí)發(fā)現(xiàn), 2020, 4(12): 26-32. [百度學(xué)術(shù)]
18
Bastian H, Glasziou P, Chalmers I. Seventy-five trials and eleven systematic reviews a day: how will we ever keep up?[J]. PLoS Medicine, 2010, 7(9): e1000326. [百度學(xué)術(shù)]
19
Dunn A G, Bourgeois F T. Is it time for computable evidence synthesis?[J]. Journal of the American Medical Informatics Association, 2020, 27(6): 972-975. [百度學(xué)術(shù)]
20
Alper B S, Richardson J E, Lehmann H P, et al. It is time for computable evidence synthesis: the COVID-19 knowledge accelerator initiative[J]. Journal of the American Medical Informatics Association, 2020, 27(8): 1338-1339. [百度學(xué)術(shù)]
21
Elkin P L, Carter J S, Nabar M, et al. Drug knowledge expressed as computable semantic triples[J]. Studies in Health Technology and Informatics, 2011, 166: 38-47. [百度學(xué)術(shù)]
22
Malec S A, Boyce R D. Exploring novel computable knowledge in structured drug product labels[J]. AMIA Joint Summits on Translational Science Proceedings, 2020, 2020: 403-412. [百度學(xué)術(shù)]
23
溫有奎, 焦玉英. 基于語(yǔ)義三元組的電子病歷潛在知識(shí)發(fā)現(xiàn)研究[J]. 情報(bào)學(xué)報(bào), 2011, 30(7): 675-681. [百度學(xué)術(shù)]
24
Li X Y, Peng S Y, Du J. Towards medical knowmetrics: representing and computing medical knowledge using semantic predications as the knowledge unit and the uncertainty as the knowledge context[J]. Scientometrics, 2021, 126(7): 6225-6251.[百度學(xué)術(shù)]
25
Kilicoglu H, Shin D, Fiszman M, et al. SemMedDB: a PubMed-scale repository of biomedical semantic predications[J]. Bioinformatics, 2012, 28(23): 3158-3160. [百度學(xué)術(shù)]
26
Elsworth B, Gaunt T R. MELODI Presto: a fast and agile tool to explore semantic triples derived from biomedical literature[J]. Bioinformatics, 2021, 37(4): 583-585. [百度學(xué)術(shù)]
27
Mons B, van Haagen H, Chichester C, et al. The value of data[J]. Nature Genetics, 2011, 43(4): 281-283. [百度學(xué)術(shù)]
28
Groth P, Gibson A, Velterop J. The anatomy of a nanopublication[J]. Information Services & Use, 2010, 30(1/2): 51-56.[百度學(xué)術(shù)]
29
Fabris E, Kuhn T, Silvello G. Nanocitation: complete and interoperable citations of nanopublications[C]// Proceedings of the Italian Conference on Digital Libraries. Cham: Springer, 2020: 182-187. [百度學(xué)術(shù)]
30
Williams A J, Harland L, Groth P, et al. Open PHACTS: semantic interoperability for drug discovery[J]. Drug Discovery Today, 2012, 17(21/22): 1188-1198. [百度學(xué)術(shù)]
31
Fabris E, Kuhn T, Silvello G. A framework for citing nanopublications[C]// Proceedings of the International Conference on Theory and Practice of Digital Libraries. Cham: Springer, 2019: 70-83. [百度學(xué)術(shù)]
32
Wong D, Peek N. Does not compute: challenges and solutions in managing computable biomedical knowledge[J]. BMJ Health & Care Informatics, 2020, 27(2): e100123. [百度學(xué)術(shù)]
33
Mons B. FAIR science for social machines: let’s share metadata knowlets in the Internet of FAIR data and services[J]. Data Intelligence, 2019, 1(1): 22-42. [百度學(xué)術(shù)]
34
Walsh K, Wroe C. Mobilising computable biomedical knowledge: challenges for clinical decision support from a medical knowledge provider[J]. BMJ Health & Care Informatics, 2020, 27(2): e100121. [百度學(xué)術(shù)]
35
杜建. 醫(yī)學(xué)知識(shí)不確定性測(cè)度的進(jìn)展與展望[J]. 數(shù)據(jù)分析與知識(shí)發(fā)現(xiàn), 2020, 4(10): 14-27. [百度學(xué)術(shù)]
36
李丹亞, 胡鐵軍, 李軍蓮, 等. 中文一體化醫(yī)學(xué)語(yǔ)言系統(tǒng)的構(gòu)建與應(yīng)用[J]. 情報(bào)雜志, 2011, 30(2): 147-151. [百度學(xué)術(shù)]
38
Swierstra T, Efstathiou S. Knowledge repositories. In digital knowledge we trust[J]. Medicine, Health Care and Philosophy, 2020, 23(4): 543-547. [百度學(xué)術(shù)]
39
Efstathiou S, Nydal R, Laegreid A, et al. Scientific knowledge in the age of computation: explicated, computable and manageable?[J]. THEORIA: An International Journal for Theory, History and Foundations of Science, 2019, 34(2): 213-236.[百度學(xué)術(shù)]
40
Smalheiser N R. Rediscovering Don Swanson: the past, present and future of literature-based discovery[J]. Journal of Data and Information Science, 2017, 2(4): 43-64. [百度學(xué)術(shù)]
41
吳家睿. 確定的不確定性與不確定的確定性——治療疾病決策與控制傳染病決策之差異[J]. 醫(yī)學(xué)與哲學(xué), 2020, 41(8): 1-6, 70. [百度學(xué)術(shù)]
42
Andermann A, Pang T, Newton J N, et al. Evidence for Health II: overcoming barriers to using evidence in policy and practice[J]. Health Research Policy and Systems, 2016, 14: 17. [百度學(xué)術(shù)]
43
Zhang L X, Wang H B, Li Q Z, et al. Big data and medical research in China[J]. BMJ, 2018, 360: j5910. [百度學(xué)術(shù)]



